GPT-5 Rapid Reaction and OpenAI Goes...Open?


GPT-5 was released today and the response was...mixed. In typical fashion, it was hyped up very hard on X: The Everything App and LinkedIn, but the release felt more like the iPhone 14 than the iPhone 3G. It did give us some really well done charts, though.
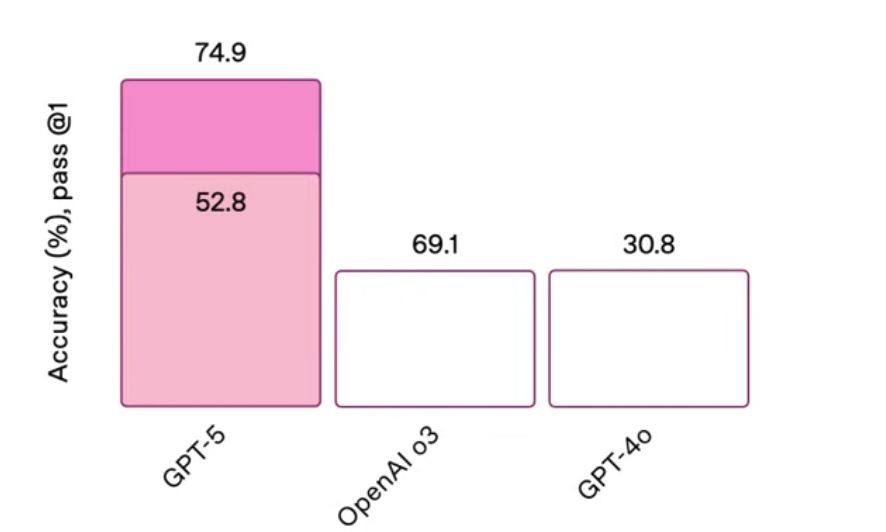
Fun with charts aside, how does GPT-5 stack up with the competition? Since it's already available in Cursor, I decided to take it for a spin to help me build out a feature on a project I'm working on. Nothing groundbreaking and probably well-represented in the training data, but that makes for an easy, low-pressure bar to clear. tl;dr it's not bad, but nothing mind-blowing.
First, the good:
GPT-5 gives a really good, detailed analysis of codebases. Leading up to this release, there were rumors swirling that OpenAI wanted to focus on coding workflows, maybe because of the popularity of Claude and Gemini. Frankly, the previous OpenAI models kind of sucked for coding tasks, and seemed to be the source of many devs' bad impressions of generative AI code assistants.
GPT-5 is a solid improvement here, and beyond the coding ability, the 'personality' of the model feels normal too, and less sycophantic than Claude or older GPT models. This is a nice reprieve given how much GPT-5 narrates what it does (I like this!). One last thing that's interesting is that it uses a mixture of models with a router behind the scenes, determining the best model for each prompt on the fly.
The bad:
First, nothing is glaringly bad. But it does feel extremely slow regardless of the actual size of the task. A few-line simple bug-fix took several minutes. This could be due to a number of factors outside of the model itself, so I'm not going to be too upset about it. Yet. If it's still an issue in a week or two, I'll go back to Claudemaxxing.
And the ugly:
It's an...ambitious model. Without prompting, it may try to write extra tests, fix irrelevant bugs, typical ambitious new grad developer stuff. It's kind of annoying, and the same thing that caused me to write off Claude Code for a short a while. And keeping in line with it being like a new grad or junior developer, it makes some silly mistakes from time to time, which take a lot of time to correct at the current speed of the model.
So, I'll keep evaluating it and see if it ends up fitting into my workflow. If it does, I might have to move over to OpenRouter to effectively use multiple models.
In other OpenAI news, OpenAI has also just dropped its latest open-weight models, which has users seeing how hard they can push their home hardware with a 20b parameter model. While open weights are not open source it's nice to see OpenAI be a little more open. This has me interested because I'm a big fan of local-first everything, especially when it comes to personal data, which is still the best way to build a real personal assistant.
Now it's time for me to get back to the salt mines (social media). Until next time!